


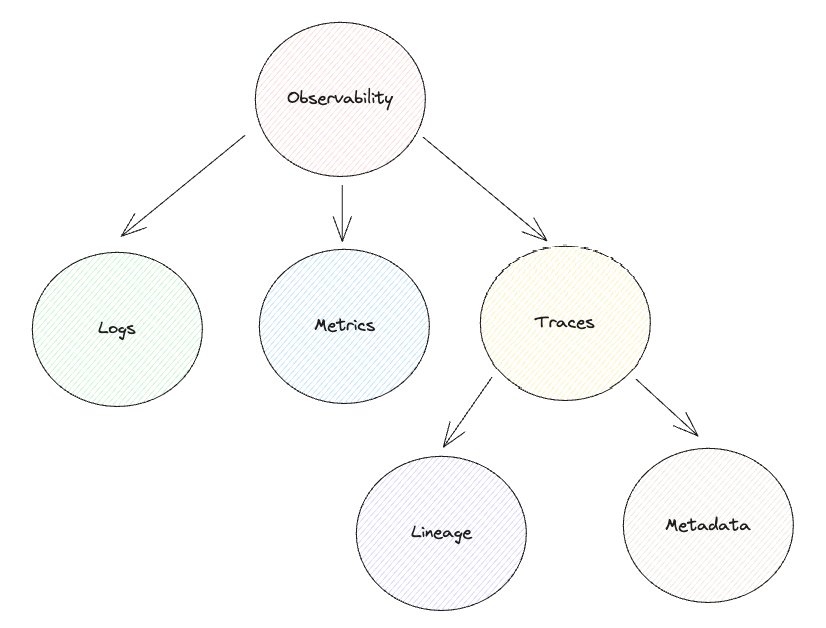
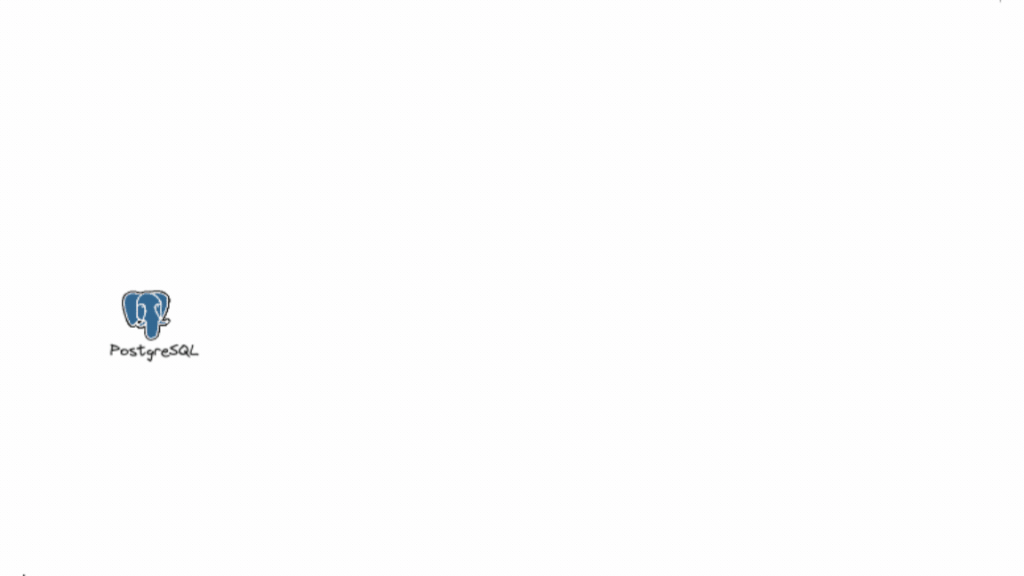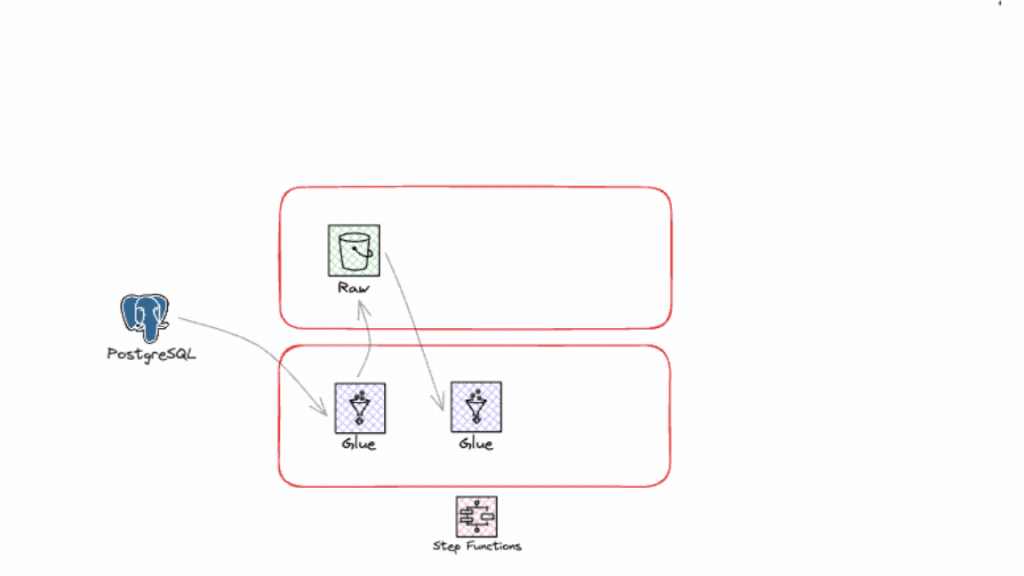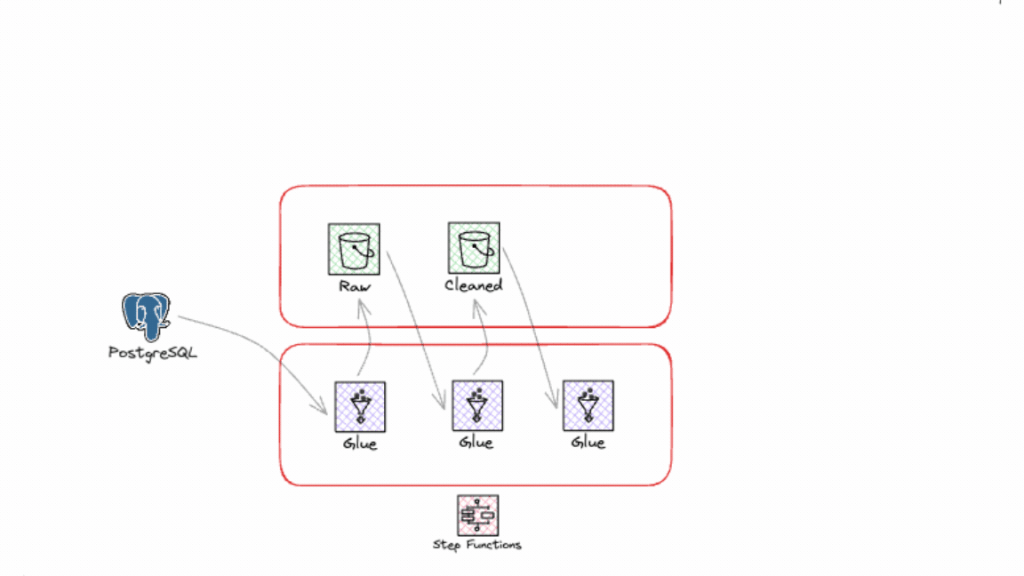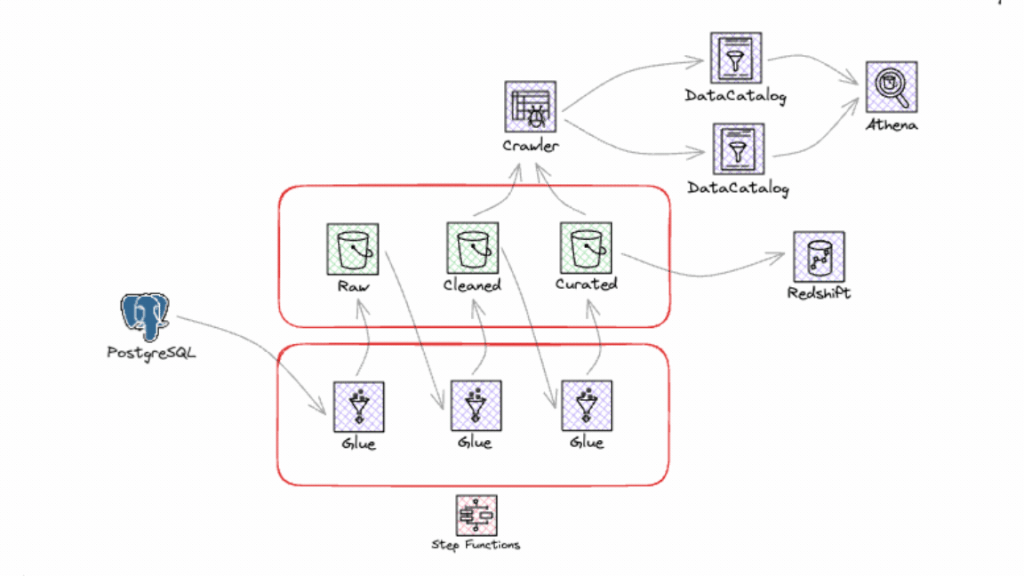
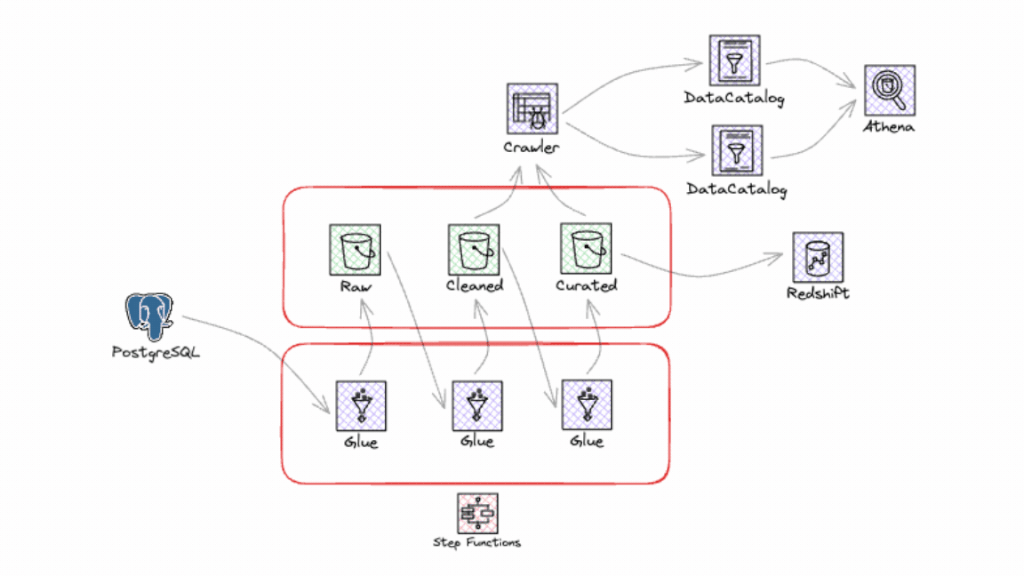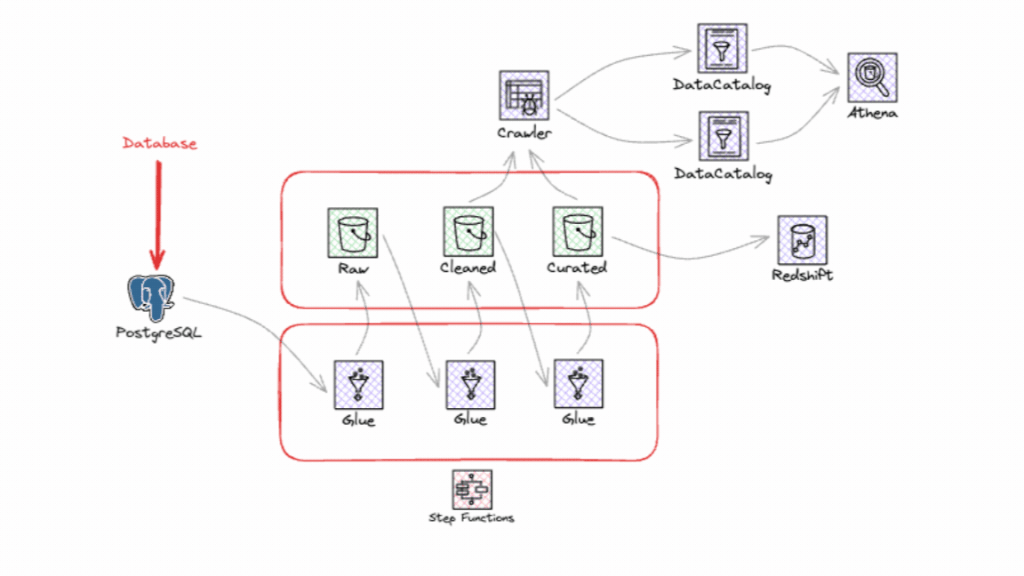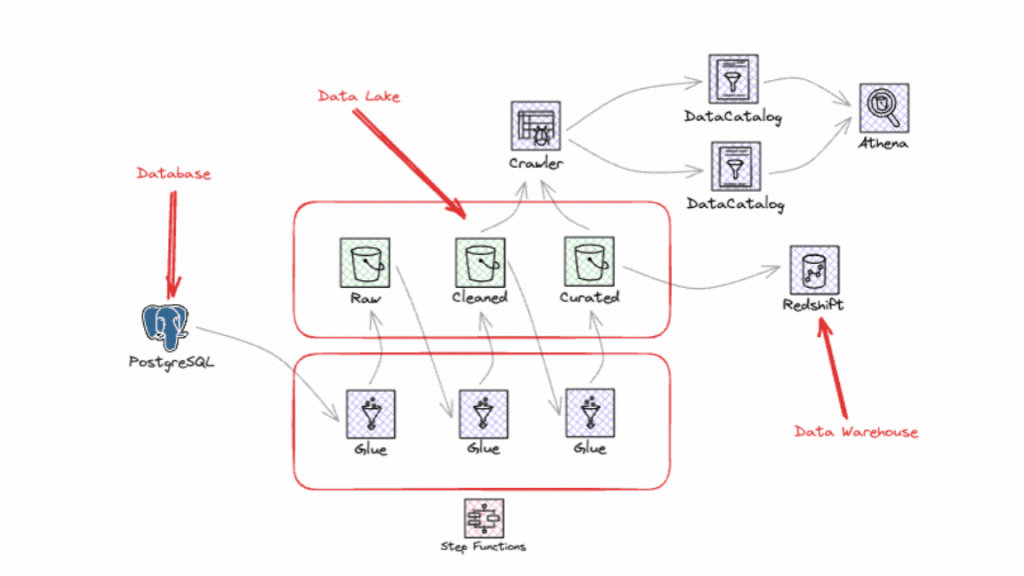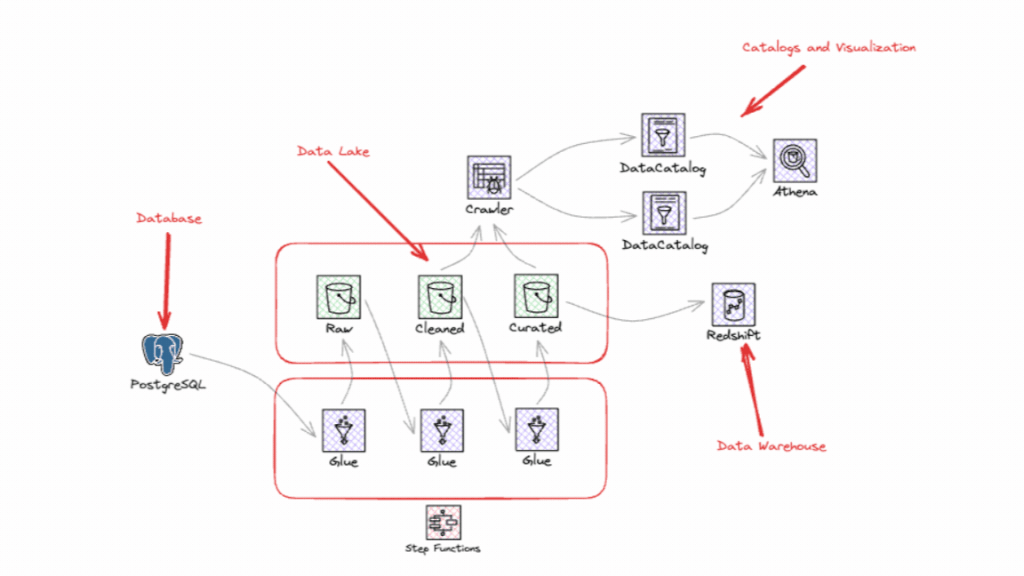
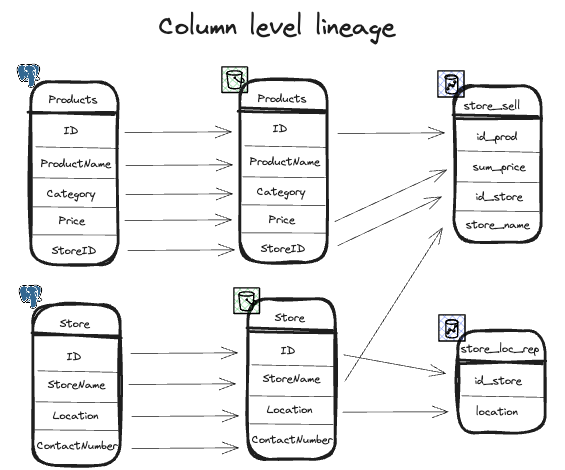
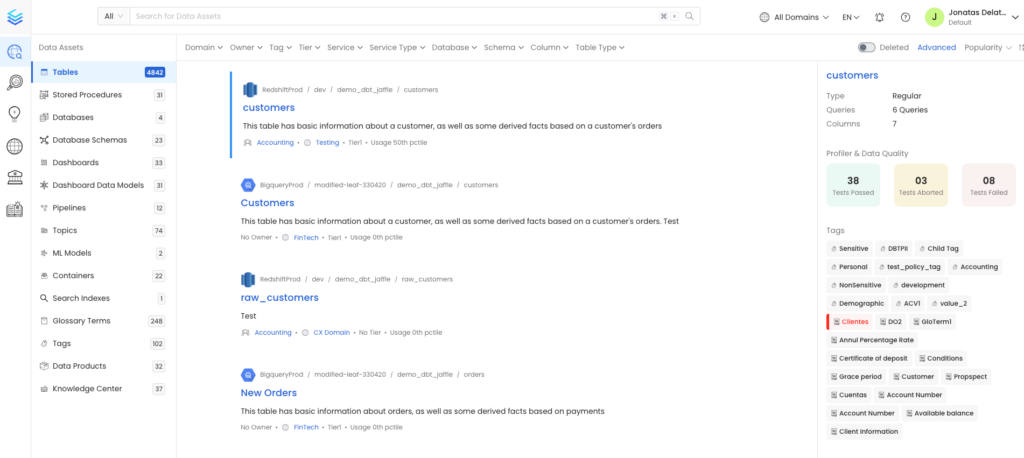
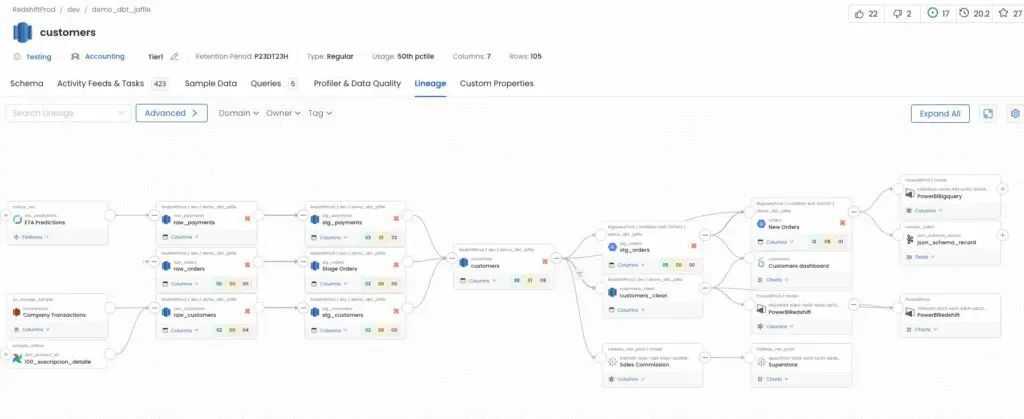
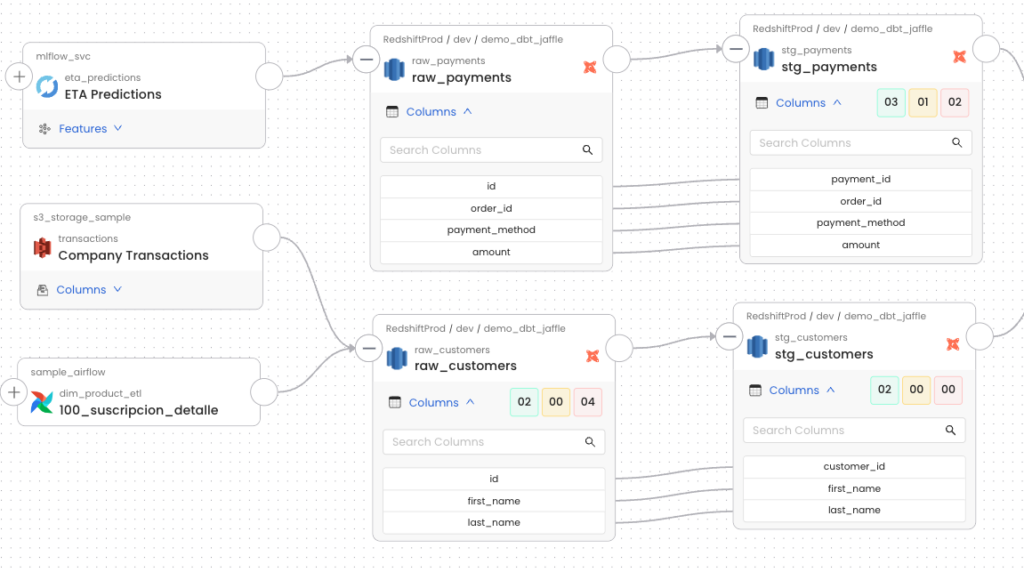


Saiba tudo o que precisa para integrar e usar esse assistente que promete revolucionar a maneira como você lida com o seu ambiente em cloud!

Times perdem 25% do tempo buscando dados. Veja como estruturar processos, tecnologia e o fator humano para máxima eficiência e entrega contínua.

Empresas que estruturam suas plataformas de dados com estratégia, segurança e governança têm mais chances de transformar promessas tecnológicas em resultados concretos. Do desenvolvimento de software com TuringBots à personalização de experiências em saúde, finanças, varejo e indústria, seu impacto já está redefinindo como as organizações operam e competem. Mas seu sucesso depende de uma base sólida de dados organizados, integração entre sistemas e governança responsável de IA, que combinados permitem que a Gen AI entregue o próximo passo no seu mercado. Baixe este e-book gratuito e descubra como impulsionar a próxima fase de inovação da sua empresa.