







Can agents follow custom processes?
When do you stop requiring human approval?
How is this different from native AI in tools like Atlassian Rovo?
How do you identify the most mature process to pilot first?


See how Banco Inter migrated to Jira Cloud, cut $200K in annual costs, and boosted team efficiency with e-Core as its implementation partner.

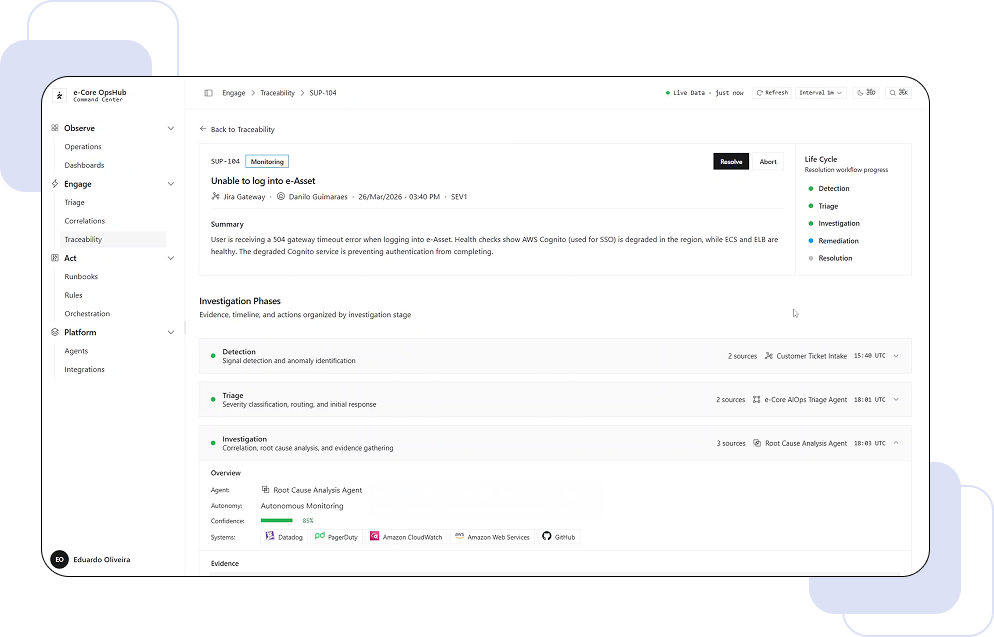
There is a belief that runs deep inside IT operations teams: a noisy environment is a healthy one. If alerts are firing constantly, if tickets are piling up, if the on-call rotation is getting hit at 2am, that means monitoring is working. The tools are catching things. I understand where this comes from. In the early days of observability, silence was genuinely suspicious. A quiet dashboard often meant a gap in coverage, a misconfigured rule, something important slipping through undetected. So teams learned to treat volume as proof, and that instinct stayed long after the environment around it changed. But noise is not proof that monitoring is working. In most cases, it is proof that something upstream was never fixed. Automation at the wrong end When alert volume becomes unsustainable, the response is almost always the same. Leadership looks at the backlog (a thousand tickets a day, engineers buried, SLAs slipping) and reaches for automation at the remediation end of the pipeline: AI agents plugged into monitoring tools, scripts that fire when incident X arrives, routing logic that moves tickets faster. These are reasonable responses to an unreasonable situation, but they treat cost rather than cause. Most of those alerts should never have been generated. Processing them faster does not change why they exist.

Senior engineers lose 30% of their time to operational overhead. Discover how Agentic AI reclaims their cognitive bandwidth and prevents burnout-driven attrition.

